

新闻视频
前瞻趋势洞察,品牌市场动态
在想象中,大模型训练也应该跟炼丹过程一样,用一堆同型号、同系列如H100组成了千卡、万卡集群,将经过预处理的数据集,拆分为多份,分配给不同的 GPU 进行训练,让数据在模型内部跑通一遍,最后根据结果再对模型进行调优、评估。
但真实的情况是因为价格因素、供应链因素等,很难凑齐一整套GPU来构建万卡集群。并且,不同GPU卡品牌参差不齐,性能差异巨大,如何能够高效组合成功克服显存墙、算力墙等瓶颈,将异构算力集群效用发挥到极致?

一般来说大模型数据训练会按照以下步骤进行:第一,实现卡间物理层面的互联互通;第二,通过合理的分布式并行策略以确保每个GPU worker只需处理部分训练状态和数据;第三,通过加速套件提升每张卡和整体的战力输出。简单归纳起来就是互联互通、并行策略、统一加速。
如单台服务器的英伟达GPU卡通过NVLink、NVSwich来保证数据在不同计算单元间的快速传输和同步。不同服务器之间的 GPU 卡通过IB或者RoCE网络连接。搞定外部通信之后,就需要依赖借助 NVIDA 开发的集合通信库 NCCL来实现卡间高速通信、数据同步,使得训练任务可以按照流程往下推进。
NCCL试图解决深度学习训练中特有的通讯问题。
这里就不得不提到最近的AI热词----NCCL(NVIDIA Collective Communications Library)。常用的集合通信库之一是 MPI(Message Passing Interface),由于在 CPU 上被广泛应用而被人熟知。而在 NVIDIA GPU 上,最常用的集合通信库则是 NCCL。它用于加速多GPU的分布式深度学习训练和推理。
通俗来理解就是它提供了一个接口,用户不需要知道哪些节点的如何相互之间通信,只需要调用接口,就可以实现GPU之间的通信。
作为GPU服务器模型训练性能的评估标准之一,NCCL可以实现单机多卡、多机多卡之间的通信,将通信方式进行整合和优化,在节点内和节点间的多个GPU上提供快速的集合通信服务,同时支持各种互连技术,包括PCIe、NVLINK、InfiniBand Verbs和IP socket,NCCL与大多数的多GPU并行化模型都能很好地兼容。
NCCL,一个完美的c++库
NCCL通过提供一系列高度优化的集体通信原语(如AllReduce、Broadcast、Reduce、AllGather、ReduceScatter等),以及点对点通信功能,使得开发者能够在多个GPU之间实现高效的数据传输和同步。
大模型训练里经常采用的主流的深度学习框架(例如 Cafe2、Chainer、MxNet、PyTorch和 TensorFlow)已集成 NCCL,便是为了在多 GPU多节点的系统上加快深度学习训练速度。NCCL既可作为 NVIDIA HPC SDK的一部分下载,也可作为适用于 Ubuntu 和 Red Hat的单独软件包下载。
NCCL主要做几件事:探测计算节点的网络设备和拓扑结构,使用算法自动调优选择一个最优的通信方式。
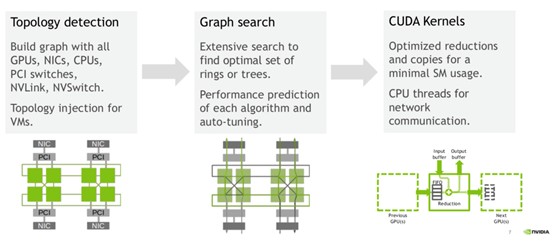
为什么要做拓扑探测?因为每个计算节点的设备情况差异比较大,每个计算节点可能有自己特定的网卡NIC,可能是InfiniBand也可能是RoCE,每个计算节点上的GPU可能是NVLink,也可能是PCIe。为了达到最优的传输效率,NCCL先要摸清当前计算节点的网络、CPU和GPU情况。之后使用调优工具,进行调优,从众多通信方式中选择一个最优方式。

基于此,我们可以得出NCCL通过优化的通信路径和数据传输策略实现了非常低的延迟和高带宽,这对于需要频繁交换数据的深度学习模型训练至关重要。而Gooxi最新推出的AMD Milan 双路4U8卡AI服务器,支持2颗高性能AMD EPYC 7003/7002系列处理器,采用CPU-GPU直连通信,是兼具性能与成本的AI服务器方案。它支持13个PICe扩展槽位,可配置8张双宽全高全长GPU,整机NCCL带宽最高可达17.22GB/S,提供多卡极致算力,可为大规模数据集上训练复杂的 AI 模型提供强劲的算力支持。它能够快速执行大规模并行计算,显著缩短模型训练时间,大幅提升大模型训练的性能和效率。
相关推荐
了解更多新闻资讯






