

新闻视频
前瞻趋势洞察,品牌市场动态
现在抢GPU卡搞智算、搞AI模型训练的都太火了。
无论你是一个游戏爱好者还是一个赛博炼丹师(大模型训练),英伟达GPU卡选型都将是绕不过的一道命题。
那么重点来了,如何在琳琅满目的各种型号GPU卡中选取一款合适且性价比高的呢?
GPU卡选型第一步是先了解自己的需求,针对不同的项目,不同的预算,做出不同选择。
针对应用场景分析
众多周知,英伟达的显卡有五个系列。
GeForce GTX系列显卡,涵盖GTX 1060、GTX 1070、GTX 1080等经典型号,现已迭代至更先进的RTX系列。
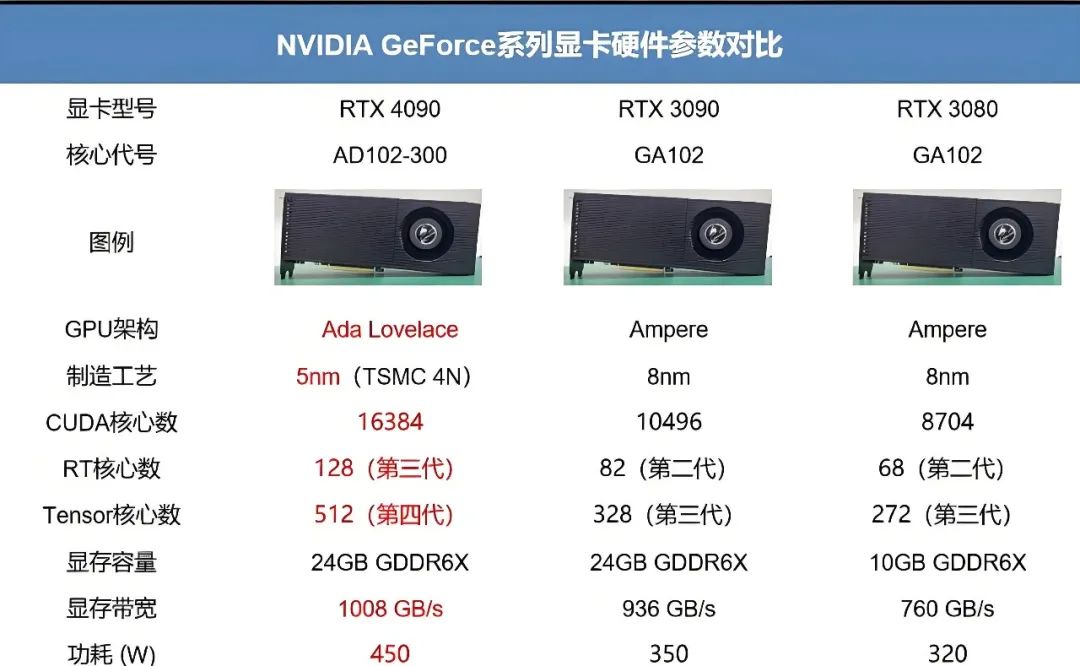
GeForce RTX系列显卡,包括RTX 2060、2070、2080及RTX 3060、3070、3080、3090、4080、4090等等型号,均搭载先进的光线追踪技术。
(2)Quadro系列:
专业图形工作站市场首选,为CAD、3D建模、渲染、动画制作提供高稳定性、高精度的优化解决方案
(3) Tesla 系列:
专为数据中心与高性能计算(HPC)打造的解决方案,支持海量并行计算,涵盖科学计算、深度学习训练与推理、大数据分析等,如我们所熟知的A100和V100就是Tesla系列的代表性产品。
(4)Data Processing Unit (DPU):
DPU是英伟达的创新产品线,专注于数据中心网络、存储和安全数据处理,显著提升数据中心运行效率和安全性能。
(5)Grace CPU 和 Grace-Hopper 超级芯片
特别注意,其中常见的三类:GeForce面向游戏,Quadro面向3D设计、专业图像和CAD等,Tesla面向科学计算,在大规模集群训练以及开发上,Tesla依旧是首选,而在单机训练上,最有性价比且能兼顾日常训练的是GeForce系列,如一直出现断货热潮的4090。
针对应用场景分析
一、计算能力。它是GPU的核心性能指标,浮点运算能力其性能的重要指标之一,尤其是在深度学习任务中,GPU需要进行大量的矩阵计算。主要评估的浮点运算能力包括:
FP64:双精度浮点数,适用于科学计算和工程模拟等高精度需求的应用。
FP32:单精度浮点数,广泛用于深度学习和机器学习的训练任务。
TF32:从A100开始引入的新数据格式,专为深度学习优化,比FP32效率更高。
BF16:用于平衡计算精度和效率的低精度浮点数格式,常见于机器学习和深度学习中。
FP16:半精度浮点数,主要用于推理任务,计算速度更快且占用的存储空间更小。
INT8:8位整数格式,计算效率高,适合推理任务。

二、显存容量,显存容量越大,能够加载和处理的数据规模就越大,特别适用于大模型训练和高分辨率图形渲染任务。
三、CUDA Core,它是NVIDIA GPU上的计算核心单元,用于执行通用的并行计算任务,是最常看到的核心类型。数量越多,GPU的并行计算性能越强。
四、Tensor Core。Tensor Core是英伟达为其高端GPU开发的一项技术,本质上是一种加速矩阵乘法的处理单元。简而言之就是:在超大规模的矩阵运算时候一旦有了Tensor Core加持,运算周期会大大缩短。人工智能训练最好选择带有Tensor Core的GPU。
针对应用场景分析
性价比是选择一张GPU最重要的考虑指标。下图是一张展现在训练和推理过程中,一美元能买到多少算力;这在一定程度上体现了英伟达众显卡的性价比。
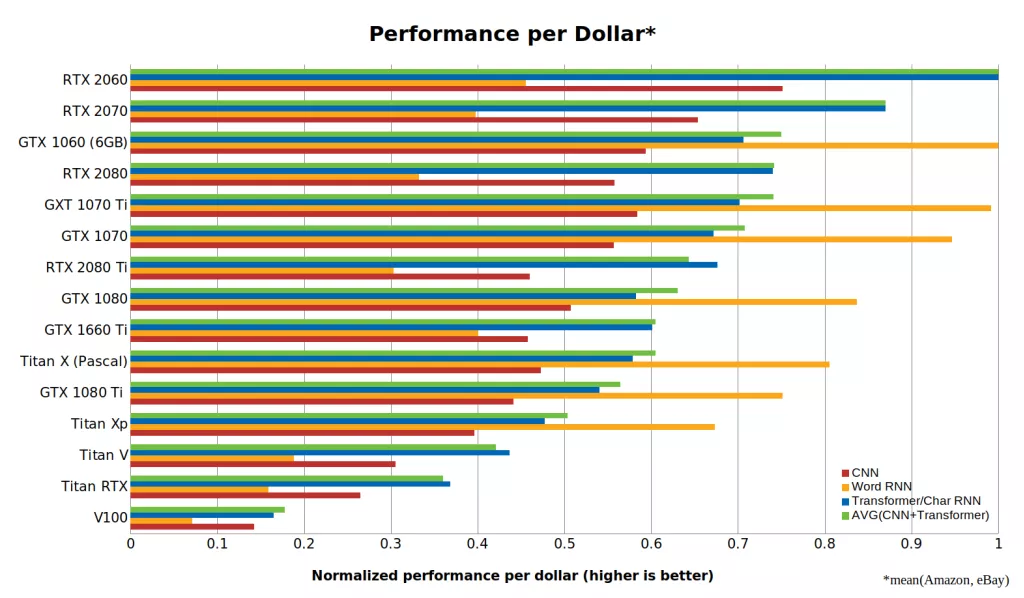
CNN、RNN和Transformer的每美元性能

当然以上的评判只是出于某个片面的功能来进行考虑,真实的GPU卡性能还与集群规模、卡间通讯效率等多种因素相关。不排除,还有任性土豪可以只选贵的。
最后一个问题,我们通常所说的RTX4090代表着什么呢?
答案即是:
RTX代表的是具有光追的中高端型号;
GTX代表的是无光追的中高端型号;
GT代表的是入门型号;
40代表的是显卡代数是目前最新的,还有30、20、10;
90代表的是显卡性能,数字越大,性能越强,还有60、70、80、90;
相关推荐
了解更多新闻资讯






