

新闻视频
前瞻趋势洞察,品牌市场动态
要说如今市面上最火爆的AI服务器机型,那必定得是GPU八卡机。在实际运用过程中,八卡机器的多GPU并行计算能力能够快速处理大量的推理请求,为加速深度学习模型的训练和推理过程提供算力支持。除此之外它还拥有强大的图形处理能力,实时渲染游戏画面。正是因为其在 AI、推理、人工智能和云游戏等领域的卓越表现,在一众的机型中脱颖而出成为热门机型。
选择一款八卡机首先面临的问题就是:选择直连机型还是拓展机型。众多周知,八卡GPU服务器通常配备更强的主板和更多的PCIe通道,以支持多卡同时高速数据传输。由于CPU自带的PCIE lan是固定且有限的,就会导致在实际应用过程的时候一些GPU卡没有多余的通信通道可用。
根据市面上常规的八卡机型,可以分为几下几种:
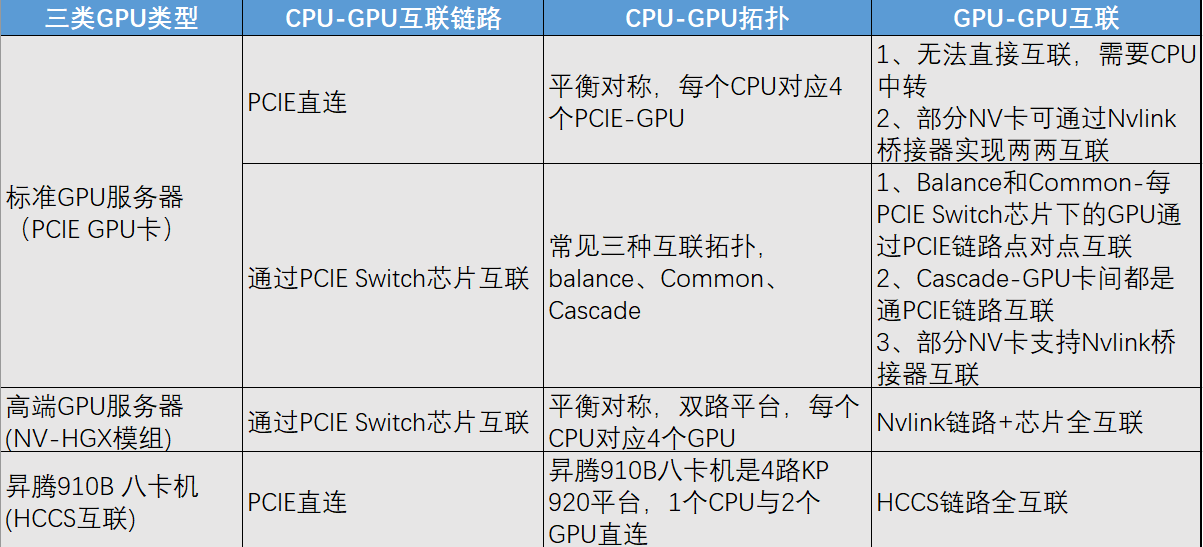
一、标准GPU服务器的CPU-GPU互联
▎直连机型
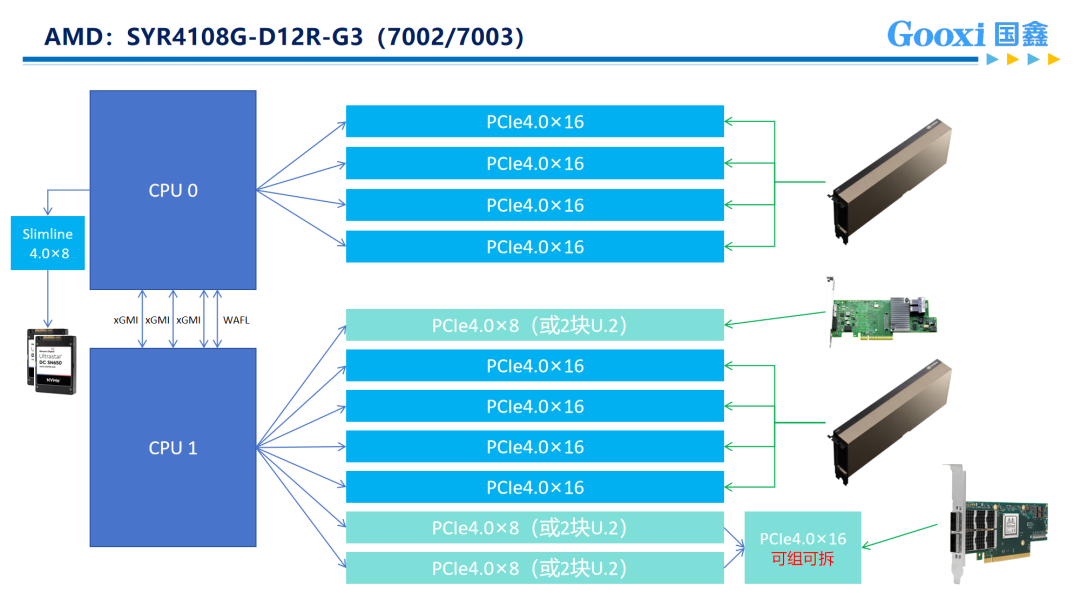
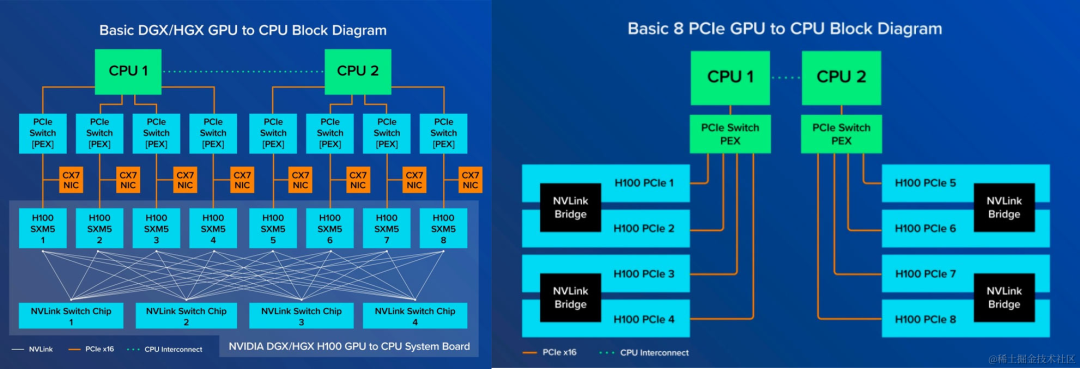
以Gooxi AMD Milan平台4U8卡AI服务器为例:它内部搭载2颗AMD第三代处理器,分为128个lan,CPU与CPU中间通过三条Xgmi联通,因而整机可提供128x2-(32x3)=160条PCIE lane。8张双宽GPU占用了16x8=128条PCIE通道后,还有剩余的32条可供其他网卡、raid卡等部件使用,因而它采用直连方式。
▎扩展机型
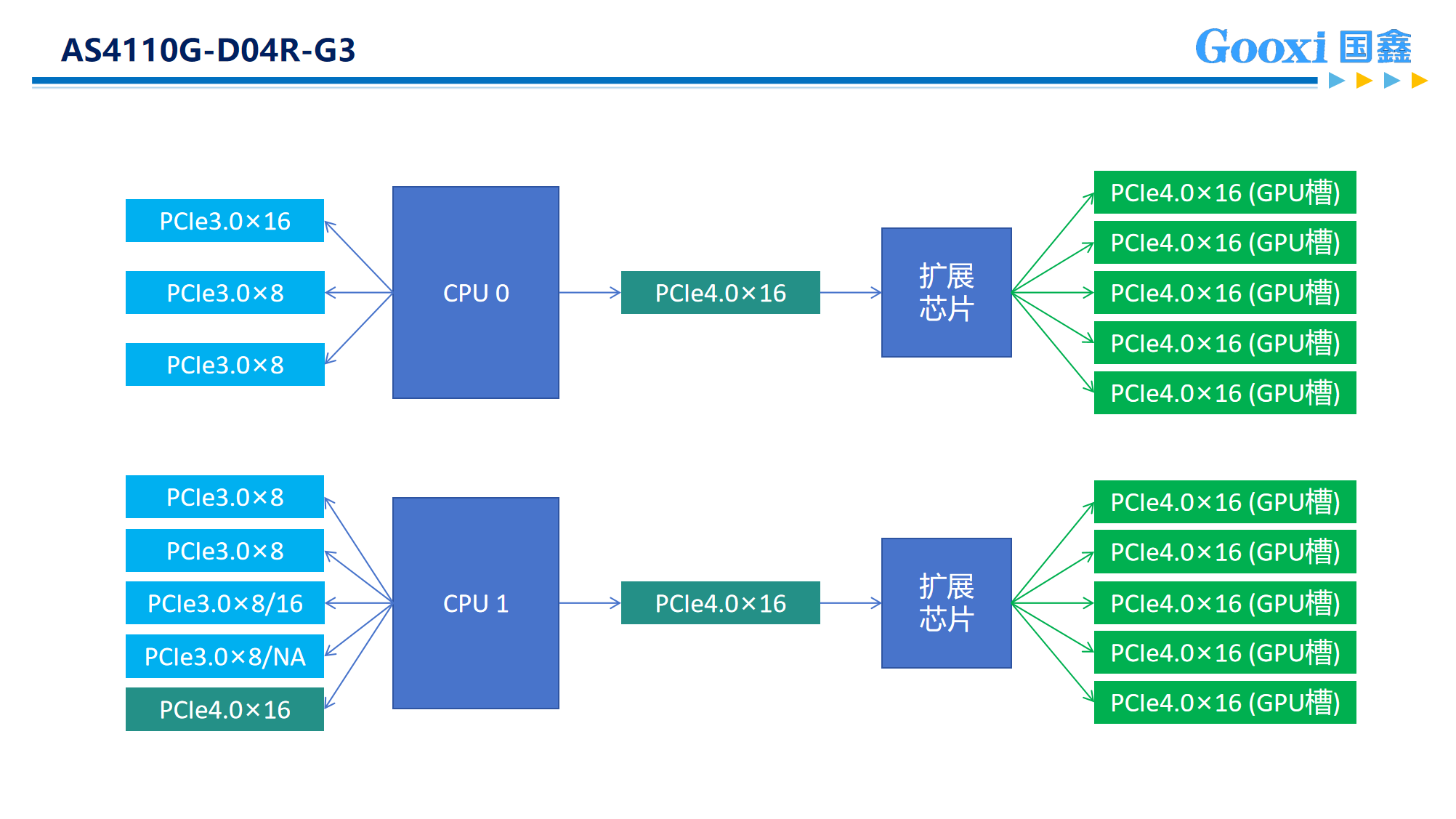
以Gooxi 的Intel Whitley平台4U10卡AI服务器为例:它内部搭载2颗第三代英特尔至强可扩展处理器,分别为64个lan,整机可提供64x2=128个PClElane,而常用的8张双宽GPU卡往往会占用掉全部的PClE lan(16×8=128),更有甚者在使用10GPU卡的情况下,PClE lan的占用更是达到了160 lan(16×10=160)。因而原本的PCIE通道不够用之后就不得不采用2个Switch芯片进行信号扩展。所以当使用扩展机型时,需要从每颗CPU各调出16个lan连接到Switch芯片,然后Switch芯片再把信号进行增强和放大处理,各扩展出5个PClE×16的槽(共10个PClE×16的槽),而CPU因为各自只调用了16个lan,所以还剩下48个lan(共96个lan)可以扩展出其他的×16或×8的PClE供网卡、RAID卡等扩展卡,或是NVMe硬盘使用。对比业内其他同平台的4U10卡服务器,Gooxi 的Intel Whitley平台,在满足10张GPU卡后,仍拥有多至8个PCIe扩展槽供网卡和RAID卡等使用,更能满足用户复杂多样的应用场景。
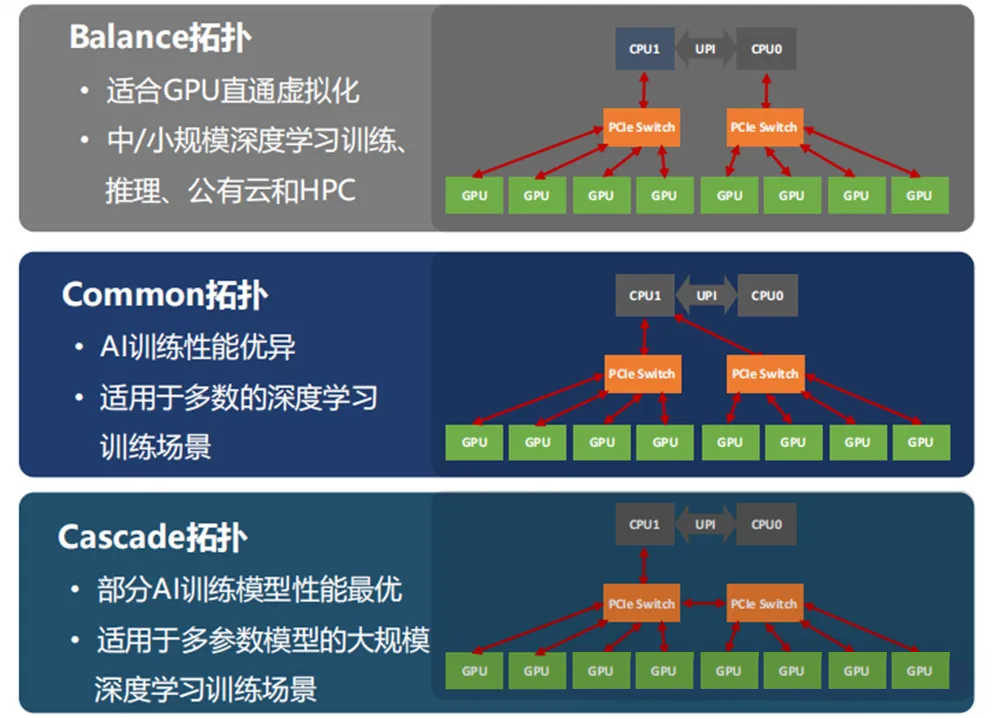
二、Switch连接的三种拓扑形式
当采用switch连接的时候,我们又会面临几种选择,是将连接的switch挂在一颗CPU上,还是分别挂在不同CPU上呢?因而产生了三种不同拓扑组合,也就是我们经常看见的balance、common、cascade三种架构。一般来说大部分厂商都是默认的balance,即左右平衡各挂一个。
▎Nvlink实现卡卡互联
此外,我们所熟知的Nvlink也是switch一种方式,但是它的switch之间是可以直接通信的,它的带宽速率远大于PCIE,或者CPU-CPU之间的UPI,同时也外联IB,提供更高效、低延迟的互联解决方案。
▎HGX超级GPU模组内部互联拓扑
HGX是英伟达推出地针对大规模计算推出的GPU卡超级模组,它主要包括了8块sxm的GPU卡、GPU互联底板、Nvlink SW芯片。SXM 架构是一种高带宽插座式解决方案,用于将 GPU 连接到 NVIDIA 专有的 DGX 和 HGX 系统。PCIe和SXM都可以用NVLink,但是SXM是更好使用NVLink的方法。
▎昇腾8卡机内部互联
不同于我们所熟知的通用服务器是2颗CPU,昇腾的8卡机内部互联拓扑是采用的4颗CPU,以昇腾HCCS 八卡机为例,它内部搭载四颗处理器,CPU和GPU采用直通模式,每颗CPU支持PCIE 4.0x40对应2个NPU。昇腾将自研高速互联技术命名为HCCS,与片内 RoCE 搭配,能实现节点间高效直连。
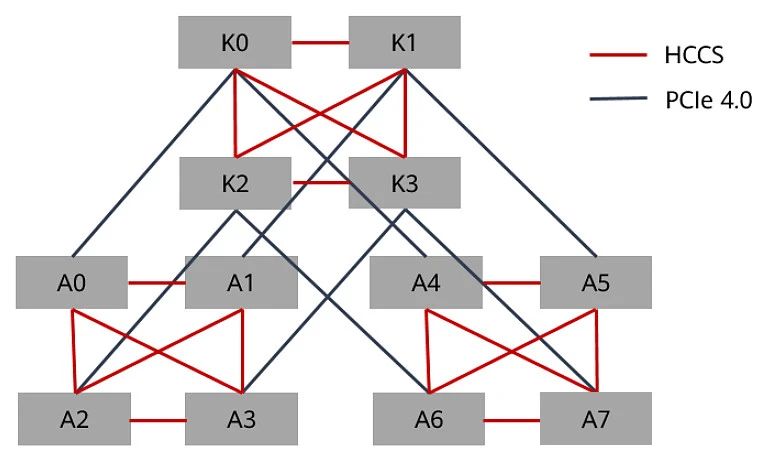
如上图对比所示,可以想象到一旦上集群搞大模型,HCCS速度会明显落后。
二、直通跟Switch连接机型区别
八卡直连机型采用GPU直连的方式在于其通信是通过CPU0→CPU1→GPU,它的通信不可避免的存在一定的延迟,因而更适合用于对信号效率不敏感且追求性价比的使用场景,如:推理、云计算等领域。
对比直连,八卡扩展机型由于采用了switch芯片,成本在一定程度上上涨,但与此同时信号传递速率更快,PCIe扩展性更高,因而适合多卡通信延迟低的场景,比如大模型多卡训练。
对比如今市面上满目琳琅的八卡机,Gooxi AMD Milan平台4U8卡AI服务器,真正做到了性能与成本的完美平衡。它的卡间通信效率高,能达17.22GB/S,有效提升大模型训练效率,并且采用AMD三代CPU,在性价比这块也是狠狠拿捏。(欢迎前来询价~)
相关推荐
了解更多新闻资讯






