

新闻视频
前瞻趋势洞察,品牌市场动态
在AI飞速发展的这几年,市场上涌现一大批诸如DPU、NPU、TPU、IPU等“XPU”的新概念,是真的存在不同的架构,还是只是一些厂商营销出来的噱头?事实上,从CPU的发展角度来看,这些XPU都不是真正的处理器。相反,他们更偏向于一种GPU,用于执行特殊工作负载的加速器。
众所周知,CPU一般由逻辑运算单元、控制单元和寄存器组成。因为CPU有复杂的数字和逻辑运算单元,并辅助有分支预测乱序执行等逻辑电路,所以CPU拥有强大的逻辑控制处理和运算能力,能够处理纵向的复杂任务。

为了减少与内存进行数据互换而造成信号延迟,CPU上使用了大量的片用来作为缓存,从而实现内存访问延迟几乎为0,相比之下,负责运算的算数逻辑单(ALU)就只占了极少的一部分,这就导致了它在处理并行计算的时候显得有些捉襟见肘,而GPU里面,单核运算处理性能稍差,控制逻辑简单且省去Cache(缓存),但ALU占比巨大,因而它可以用来处理高强度的横向图形计算,提升并行计算效率。
但是,GPGPU每个核心拥有的缓存相对较小,核心的逻辑功能简单,只能执行有限种类的逻辑运算操作。GPGPU内部的核心通常被划分成若干个组,组内核心不能独立工作运行,需要协同工作共同完成运算任务。
为了解决GPU效率问题,GPGPU由此诞生,得益于shader( Shader(着色器)是一段能够针对3D对象进行操作、并被GPU所执行的程序)的出现,GPU在图形流水线中引入了可编程性,从此GPU能做的事情不再局限于图形数据的处理,而将触角延伸至其他计算密集的领域,开启了GPGPU时代。
GPUGPU全称通用计算图形处理器(General Purpose GPU),是一种强大的计算工具,能够协助CPU进行非图形相关的复杂运算。

在GPGPU架构设计中,摒弃了GPU的图形显示部分,将其余部分全部投入通用计算,并成为AI加速卡(一种并行计算硬件)的核心。因此它能高效地搬运、运算和处理海量数据以及高并发数据,主要用于例如物理计算、加密解密、科学计算以及比特币等加密货币的生成。
Cuda——
作为一种芯片架构,目前英伟达主流的GPUGPU框架是CUDA,它采用并行计算框架,允许开发者使用C语言在上面进行二次开发,并且在英伟达的CPU上执行。它的特点是基于C语言,易于上手,并且提供了丰富的库,以及各种工具,方便开发者进行高性能计算,CUDA提供了各种nvprof、Nsight来帮助开发者优化代码性能。
OpenCI——
0penCl(Open Computing Language)是一个开放的标准,支持多种类型的计算设备,包括CPU.GPU、FPGA等。它由Khronos Group维护,旨在提供跨平台的并行编程能力。0penCL能够在不同厂商的硬件上运行,如AMD、Intel、NVIDIA等。它支持多种设备和架构,提供了灵活的编程接口。作为开放标准,0penCL拥有广泛的社区支持和文档资源。
Vulkan——
Vulkan是Khronos Group推出的一种低开销、高效能的图形和计算API。主要用于图形渲染,也能够提供强大的计算能力。
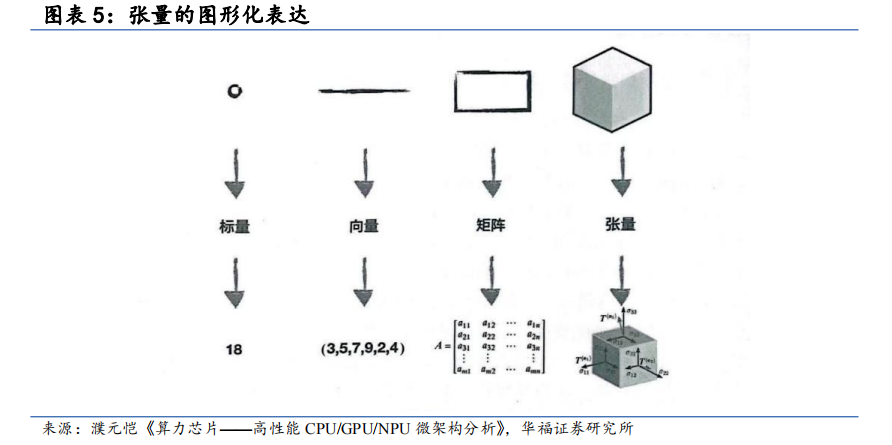
GPGPU的出现能够有效解决类似并发场景CPU效率低的问题。但实际上大多程序会因为等待访问而导致效率低下,且管理和组织大量程序会付出巨大的硅片面积代价和内存带宽的代价,为了提升GPGPU的工作效率,TPU(张量处理器)应运而生。它全称Tensor Processing Unit,是一种专为处理张量运算而设计的ASIC芯片,由谷歌在2016年推出。在深度学习的世界里,张量(多维数组)是无处不在的,TPU就是为了高效处理这些张量运算而诞生的。这三者是从通用到专用不断演进的过程。
而所谓的NPU(Neural network Processing Unit), 即神经网络处理器。NPU处理器专门为物联网人工智能而设计,用于加速神经网络的运算,解决传统芯片在神经网络运算时效率低下的问题。TPU是由谷歌发布的因而只能被广泛应用于 Google 的云基础设施,而 NPU 作为一种针对 AI 任务进行定制AI芯片,一般都集承在特定的AI设备中,例如智能手机和物联网 (IoT) 设备。
相关推荐
了解更多新闻资讯






